
I am currently pursuing a PhD at Fudan University under the supervision of Prof. Dahua Lin. Additionally, I am an intern at the Shanghai AI Laboratory, where I am mentored by Yuhang Zang.
My research interests lie in multimodal large language models (MLLMs), video understanding, and efficient reasoning. I am passionate about contributing to impactful and meaningful research. If you’re interested in my work, please feel free to reach out to me via email (wiselnn570@gmail.com) for potential collaboration.
🔥 News
- [2025-05-01] One paper, VideoRoPE, is accepted by ICML 2025 as oral presentation.
- [2024-09-28] Two papers, ShareGPT4Video and MMDU, are accepted by NeurIPS2024.
📝 Selected Publications

VideoRoPE: What Makes for Good Video Rotary Position Embedding?[Accepted by ICML2025 as Oral Presentation!]
Xilin Wei*, Xiaoran Liu*, Yuhang Zang📧, Xiaoyi Dong, Pan Zhang, Yuhang Cao, Jian Tong, Haodong Duan, Qipeng Guo📧, Jiaqi Wang📧, Xipeng Qiu, Dahua Lin
This work introduces VideoRoPE, which addresses four key properties essential for RoPE in video applications. By incorporating Low-frequency Temporal Allocation (LTA), Diagonal Layout (DL), and Adjustable Temporal Spacing (ATS), VideoRoPE effectively meets these requirements. We also present the V-NIAH-D retrieval task to expose the limitations of current position embedding designs, especially in frequency allocation. Our findings show that existing Video LLMs are prone to frequency-based distractors. Extensive experiments demonstrate that VideoRoPE consistently outperforms other RoPE variants.

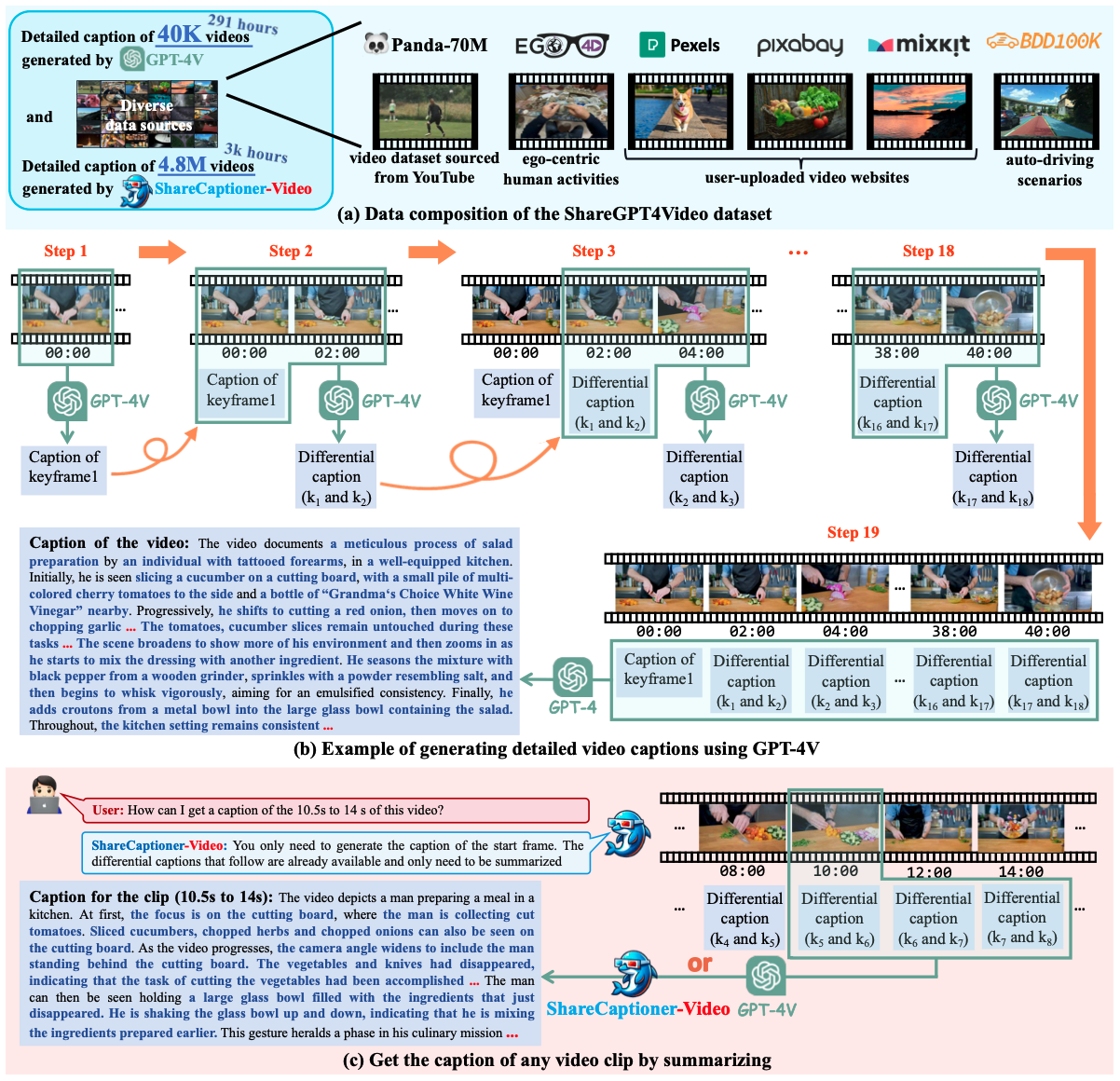
ShareGPT4Video: Improving Video Understanding and Generation with Better Captions[Accepted by NeurIPS2024!]
Lin Chen*, Xilin Wei* Jinsong Li*, Xiaoyi Dong*, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Bin Lin, Zhenyu Tang, Li Yuan, Yu Qiao, Dahua Lin, Feng Zhao📧, Jiaqi Wang📧
This work introduces a large-scale, highly descriptive video-text dataset, including 40K GPT-4 Vision-generated video captions and around 400K implicit video split captions. We also present a versatile video captioner that handles various video durations, resolutions, and aspect ratios, closely matching GPT-4 Vision’s captioning capability, with two inference modes optimized for quality and efficiency. Additionally, we introduce the ShareGPT4Video-8B, a superior large video-language model that trains for 5 hours on 8xA100 GPUs. Finally, we improve Text-to-Video performance by leveraging high-quality video captions generated by our ShareCaptioner-Video, powered by Open-Sora-Plan.

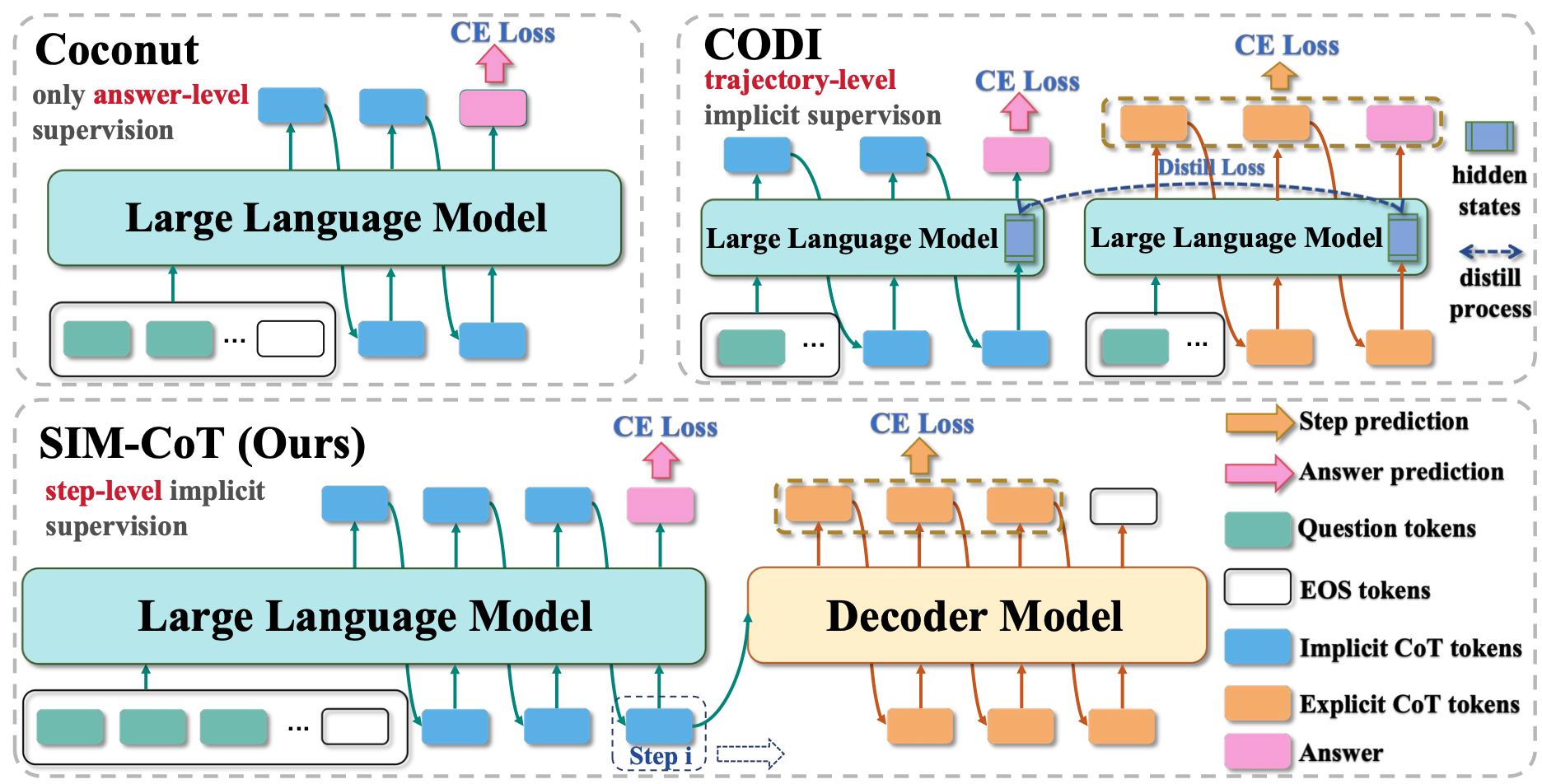
SIM-CoT: Supervised Implicit Chain-of-Thought
Xilin Wei, Xiaoran Liu, Yuhang Zang📧, Xiaoyi Dong, Yuhang Cao, Jiaqi Wang📧, Xipeng Qiu, Dahua Lin
This work analyzes the limitations of implicit Chain-of-Thought (CoT) methods, highlighting a latent instability issue where increasing implicit tokens leads to collapsed, homogeneous latent states that lose operator semantics. We propose SIM-CoT, a plug-and-play module that introduces step-level supervision via an auxiliary decoder, stabilizing optimization and ensuring meaningful reasoning steps. SIM-CoT outperforms explicit and implicit baselines, surpassing GPT-2’s supervised CoT by +2.1%, Coconut by +8.2%, and CODI by +4.3%, with improvements of +1.5% to +9.0% on larger LLaMA models (1B/3B/8B). It remains stable even with 8–16 implicit tokens, where prior methods collapse, and adds no extra inference cost since the auxiliary decoder is discarded after training, while also offering interpretability by decoding each latent token into human-readable steps.

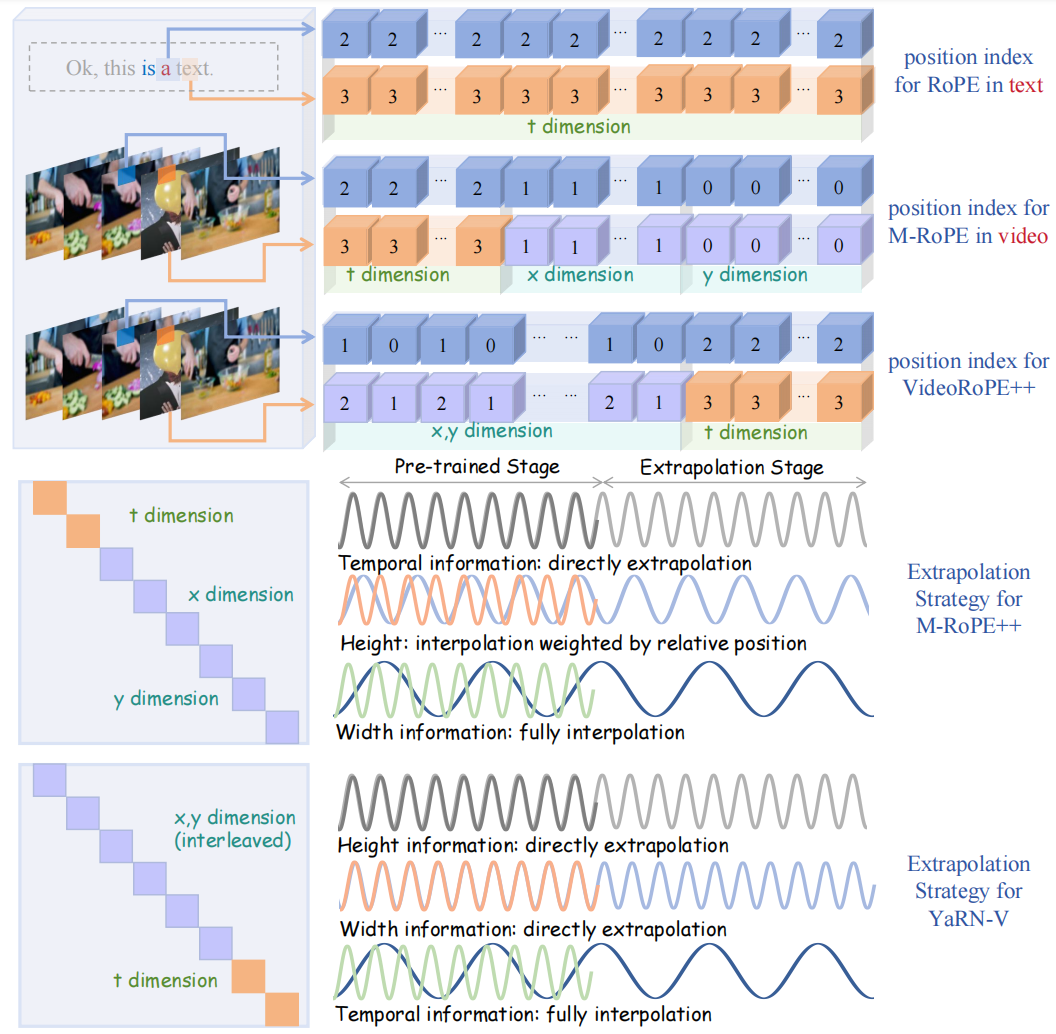
VideoRoPE++: Towards Better Video Rotary Position Embedding
Xilin Wei, Xiaoran Liu, Yuhang Zang📧, Shengyuan Ding, Xiaoyi Dong, Pan Zhang, Yuhang Cao, Haodong Duan, Qipeng Guo, Jiaqi Wang📧, Xipeng Qiu, Dahua Lin
In this work, we propose VideoRoPE++, which improves upon VideoRoPE by introducing YaRN-V for training-free further context extrapolation. We also enhance the V-NIAH-D benchmark with the more challenging V-RULER task, which includes multi-key retrieval, lengthy multimodal stacks, needle retrieval under distractors, and counting and ordering tasks. Experiments demonstrate that VideoRoPE++ consistently outperforms other RoPE variants, achieving significant improvements in long video retrieval (+12.4 on V-NIAH, +12.4 on V-NIAH-D), video understanding (+2.9 on LongVideoBench, +4.5 on MLVU, +1.7 on Video-MME), and hallucination reduction (+11.9 on VideoHallucer).
🎖 Honors and Awards
- National Scholarship Award, PRC, 2020.
- National Scholarship Award, PRC, 2022.
- National Scholarship Award, PRC, 2023.
📖 Educations
- 2024.09 - until now, PHD, Fudan University.
📌 Activities
- Conference reviewer of NeurIPS 2025, CVPR 2026, ICLR 2025/2026, COLM 2025.